Spiders是什么意思?搜索引擎Spider是什么意思?
日期:2024-03-01 作者:攻硬营销
Spiders英文释义:互联网上的蜘蛛;蜘蛛;网页爬虫;搜索引擎Spider也就是大家常说的爬虫、蜘蛛或者机器人。是指自动抓取网页内容的机器人,是处于整个搜索引擎最上游的一模块,是搜索引擎用来访问Internet上网页的自动程序。spiders根据html的语法和格式,对读取的页面进行代码过滤,收入相关的文字内容。搜索引擎无法象人那样去读相应的图片、Flash、影片里面的内容。图片中的文字对Spider来说毫无意义。对于javascript里面的文字内容,会开始收录。

世界各大常见的搜索引擎Spiders名字,方便大家查看网站日志时查找:
google蜘蛛: googlebot
百度蜘蛛:baiduspider
yahoo蜘蛛:slurp
alexa蜘蛛:ia_archiver
msn蜘蛛:msnbot
altavista蜘蛛:scooter
lycos蜘蛛: lycos_spider_(t-rex)
alltheweb蜘蛛: fast-webcrawler/
inktomi蜘蛛: slurp
搜狗蜘蛛:Sogou spider
新浪爱问蜘蛛:Iaskspider
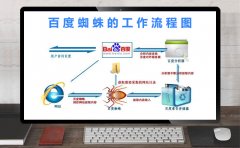
在大型搜索引擎spider的抓取过程中会有很多策略,有时也可能是多种策略综合使用,这里简单介绍一下比较简单的spider抓取策略,以辅助大家对spider工作流程的理解,spider抓取网页,在争取抓取尽可能多网页的前提下,首先要注意的就是避免重复抓取,为此spider程序一般建立已抓取URL列表和持抓取URL列表。实际中是由哈希表来记录URL的两个状态;在抓取到一个新页面时,提取该页面上的链接,并把提取到的链接和已经抓取URL列表中的链接进行逐一对比,如果发现该链接已经抓取过,就会直接丢弃,如果发现该链接还未抓取,就会把该链接放到待抓取URL队列的末尾等待抓取。只有被spider抓回的页面或URL才会被索引和有机会参考排名。需要注意的是:主要是spider抓到的URL都可能会参考排名,但参考网页并不一定就被spider抓取到了内容,比如有些网站屏弊搜索引擎spider后,虽然spider不能抓取网页内容,但是也会有一些域名级别高的URL在搜索引擎中参考了排名,所以高权重的域名和网站关键词的排名密切相关。