网络爬虫程序分为几类,常见的爬虫种类
日期:2024-03-01 作者:攻硬营销
网络爬虫就是为搜索引擎平台提供信息来源的程序,网络爬虫又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本,已被广泛应用于互联网领域。互联网上的爬虫程序非常多,有好有坏,不常见的不做太多列举。常见的爬虫种类有:

一,Google爬虫。算法优秀,反应速度迅速,对内容质量把握优秀,中等强度爬虫程序,对服务器负担不大,推广效果好。
对应user-agent: 爬虫名称
Googlebot:google 网页爬虫程序
Googlebot-news:google 新闻爬虫程序
Googlebot-image:google 图片爬虫程序
Googlebot-video:google 视频爬虫程序
Googlebot-mobile:google 移动爬虫程序
Mediapartners-google 广告爬虫程序
Mediapartners(googlebot):google广告爬虫程序
Adsbot-google:google 着陆页质量检测爬虫程序
二:百度爬虫程序。算法良好,反应速度迟钝,对内容质量把握一般,高强度爬虫程序,隐私保护性差,在百度面前无隐私可言,推广效果好。
对应user-agent: 爬虫名称
Baiduspider: 百度网页爬虫兼移动爬虫程序
Baiduspider-image: 百度图片爬虫程序
Baiduspider-video: 百度视频爬虫程序
Baiduspider-news: 百度新闻爬虫程序
Baiduspider-favo: 百度搜藏爬虫程序
Baiduspider-cpro: 百度联盟爬虫程序
Baiduspider-ads: 百度商务爬虫程序
三:好搜(即360)爬虫程序。类似百度早期算法,反应速度迟钝,对内容质量把握不足,高强度爬虫程序,隐私保护性差,需要翻墙的小伙伴千万要避开。推广效果好。
对应user-agent: 爬虫名称
360spider或haosouspider: 好搜网页爬虫兼移动爬虫程序
360spider-image: 好搜图片爬虫程序
360spider-video: 好搜视频爬虫程序
四:搜狗爬虫程序程序。算法一般,反应速度迟钝,不能良好的把握内容质量,高强度爬虫程序,由于算法奇差,会对页面进行大量反复而又无实际意义的扫描,对服务器负担很大,推广效果差!严重的内部点击,非常讨厌。搜狗本身流量很少,收录慢,抓取压力大,综合性价比非常低。
对应user-agent: 爬虫名称
Sogou spider: 搜狗综合爬虫程序
五:新浪爱问爬虫程序。基本可以当作搜狗爬虫,各项性能恶劣,推广效果差。
对应user-agent: 爬虫名称
Iaskspider: 新浪爱问爬虫程序
六:有道爬虫程序。基本可以当作搜狗爬虫,各项性能恶劣,对服务器负担较搜狗略低,推广效果差。
对应user-agent: 爬虫名称
YodaoBot: 网易有道爬虫程序
七:Alexa爬虫程序。Alexa爬虫,用于检测网站是否做了Alexa排名作弊,如果不关心Alexa排名的可以遮蔽。一般企业站看这个没意思很难有排名的。
对应user-agent: 爬虫名称
ia_archiver: Alexa爬虫程序
八:雅虎爬虫程序。算法优良,反应速度还可以,高强度爬虫程序,有时候会从多个ip地址启动捉取,算是比较规范的爬虫,推广效果还可以。不过自从雅虎离开大陆,而且在11年11月左右雅虎关闭了站长服务并把数据转移到必应。
对应user-agent: 爬虫名称
Yahoo! Slurp: 雅虎爬虫程序
九:必应爬虫程序。整体性能还不能判断,不过根据最近世界搜索引擎市场份额占比判断,性能应该接近百度甚至比百度要好,国内本土化不足。来自必应的流量不少于好搜。
对应user-agent: 爬虫名称
Bingbot: 必应爬虫程序
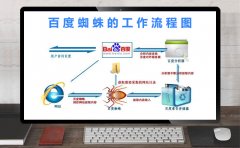
大概常见的爬虫种类就有这些,别的基本可以直接遮蔽了。注:只要不给链接入口搜索引擎是不好抓取的。网络爬虫是一个自动提取网页的程序,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。